单机运行大量容器时遇到的奇怪网络问题
该文章根据 CC-BY-4.0 协议发表,转载请遵循该协议。
本文地址:https://fenying.net/post/2024/07/07/arp-insides-large-machine-with-great-many-containers/
我们有一台开发用的机器,上面运行了大约 100 多个 NodeJS 容器,全部都在同一个 docker 网络中,彼此之间通过容器名称路由互联。
最近遇到的一个奇怪问题是,容器之间通信时,经常报 getaddrinfo EAI_AGAIN 错误,即 DNS 查询失败。
起初我们以为是机器的负载能力问题,因为此时内存确实消耗得差不多了,于是运维团队给机器加大了内存,但是问题并未解决。 此时无论看 CPU、内存、磁盘、网络、ulimit 等指标,都没有发现异常。
后来在 Google 里搜了好久,网上有类似的问题,但并没有涉及到大量容器的情况,大概说明是如下两个可能:
moby项目的 Github 仓库中有人反馈,使用node:alpine镜像时,容器内部的 DNS 查询会出现问题,虽然没有说明原因,但是至少给了个解决方案:自建 DNS。- 还有人反馈是 Docker 的问题,其自建 DNS 对容器名的解析有性能问题,但是没有给出具体的解决方案。
然而事实上,这个问题并不完全只是表现在 DNS 查询上,而是在容器之间的通信上都会出问题,比如时不时就无法连接到各个容器,此时是网络超时而不是 DNS 查询失败。
无解,运维怀疑是系统本身的问题(CentOS 7,内核也很古老,安装以后从未更新过……),恰好我们要迁移机房,于是换了台机器装了最新的 Debian,把这些容器迁移过去。
刚开始确实没有问题,但是容器的迁移不是一次性完成的,而是逐步迁移的,因此刚开始迁移的时候并未复现问题。直到几乎所有容器都迁移过去后,问题又出现了。
这次我找运维要了一份 dmesg 日志,不过由于日志实在太多了(大量由于容器启停产生的网卡日志),最后我终于根据同事复现问题的时间抓到了一点蛛丝马迹:
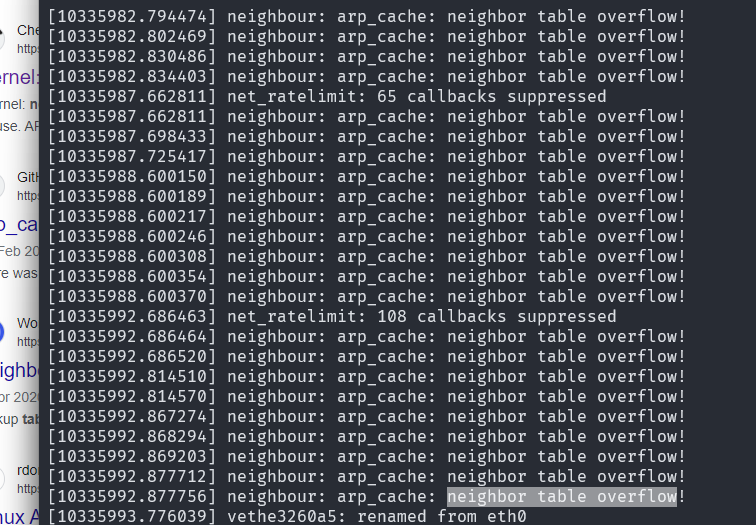
哦?ARP 缓存表炸了?
我查了下系统的 ARP 缓存表大小:
1sysctl net.ipv4.neigh.default.gc_thresh1
emmmm,默认值是 128。调大一点试试?
1echo 'net.ipv4.neigh.default.gc_thresh1 = 4096' >> /etc/sysctl.conf
2echo 'net.ipv4.neigh.default.gc_thresh2 = 8192' >> /etc/sysctl.conf
3echo 'net.ipv4.neigh.default.gc_thresh3 = 16384' >> /etc/sysctl.conf
4
5sysctl -p
自此,问题消失……